As the title suggests, I’m wondering about the performance hit from encrypting your NVME drive. Is it something that is appreciable?
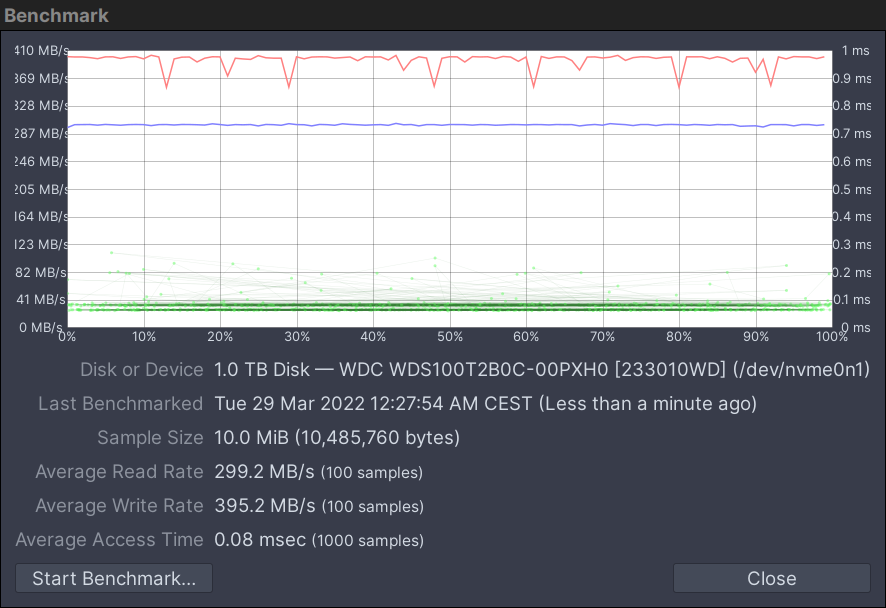
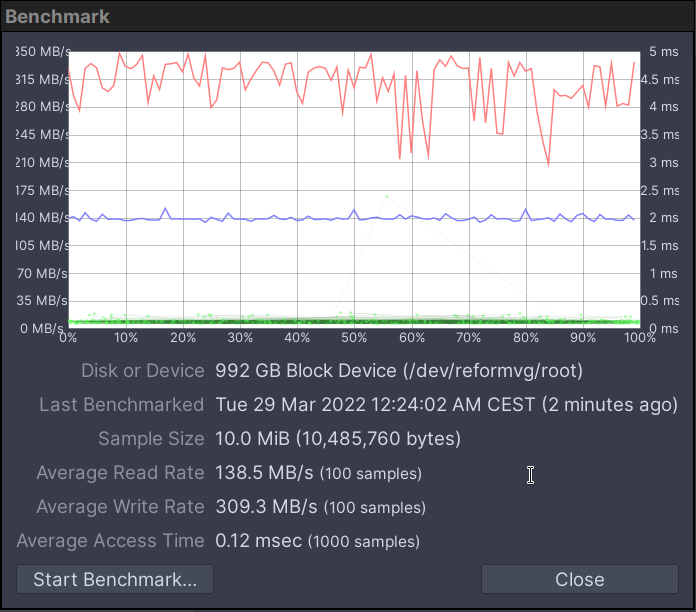
7 Likes
That is one dimension of the performance question, but I am also curious about how much CPU overhead is needed with full disk encryption. Does the Reform have hardware to offload encryption from the CPU?
Here is the CPU utilization during the benchmark. Notice the bump on the graph between -23 seconds and -12 seconds where all four CPUs go up to 40%:

7 Likes
Thanks for this! I knew to expect some impact, but it is nice to see the realistic impact that it would have. I appreciate all of the work you put into showing me this stuff!
1 Like
For sure an answer that includes real-life tests with graphic depictions is Phoronix-level stuff!! Good on yaz (all of yaz)!
Fundamentally if you choose full disk encryption (FDE) using something like LUKS, your performance hit will be the largest. I’ll be posting a script to autocreate a LUKS ‘/’ and ‘swap’ on a target device of choice shortly.
If you elect to ONLY encrypt your home directory it’s a much smaller hit, as none of the OS has to deal with any of that encrypted stuff, mostly your applications (i.e. browser, email clients, graphics, etc.) open, read/write, close files.
The performance hit on LUKS is because what happens is that once you’ve mounted your ‘/’ partition every input/output operation (IOPS) has to go through this process:
- App takes the data you want to write to a file and send it to the OS.
- OS sees a (likely ext4) partition and writes to it.
- LUKS takes a block of data and encrypts it.
- LUKS takes the encrypted block of data and writes it to the underlying container.
- File system (FS) figures out where to write that block as an (likely) ext4 block inside that container.
- Unwind the stack.
Because it’s block oriented, everyone waits to get the full block without processing it until it’s all there. That adds a latency (or for those who hate that word for non-network things, copy after read, or copy after write, or anything other than copy-while-read) and that latency is n times the block size. In this case steps 3-5 --as efficient as they may be at buffer allocation and reusing buffers and passing pointers instead of a copy operation-- still take those 3 steps for EVERY block.
There is no as-of-today FDE that isn’t block oriented.
Ethernet switches have the header at the front end of a frame (like “packet” only of fixed size) and so can start switching before receiving the whole frame.
Wavelength Division Multiplexing (WDM) uses prisms and filters to passively switch a multi-`channel’ light beam into different light paths on fiber-optic devices. This occurs regardless of framing.
Block devices unfortunately must treat blocks as a holistic unit. In this case from the bottom up we have:
0 - Physical layer. Data are written to the device.
1 - Block layer. That data is put together in a certain sizing at a certain place. These are often called “sectors” on storage devices in an homage to the obsolete terms floppy-disk drives used and later modified for hard-drive use (Cylinder, Head, Sector, or CHS). On today’s USB sticks and nVME devices, it’s just a *****on of bytes… but the sectorization causes this problem.
It’s a tradeoff. If you set the logical sector size to 1MB and choose a computationally inexpensive checksum like BTRFS’ 32-bit cyclic redundancy check (CRC) then you’ll perform 1/256th the number of calculations as if you did 4096B default NVMe sector/block size. Now take that and multiply it by 3 as we have to do for steps 3-5 and you’d have a reduction to 1/(256*3) or 1/768. That’s almost 3 orders of magnitude and is EXTREMELY significant.
One more comment. Core CPUs at 40% doing all this layering work… if it could be more efficient that would put them at roughly 0.07%.
The same happened when CPUs that previously did virtual machines (VMs) in software (e.g. VMware) started supporting virtualization and then when the software adapted (Red Hat virtualization, KVM, VMware ESX, etc.) performance was up two orders of magnitude.
Great question. Great data on the response. Now if someone will just De-1985 the kernel, FS, LUKS, etc. to go to a stream oriented setup… everything will be a complete disaster for a couple of years but then once the bugs are gone… performance will be awesome. I don’t think Linus has the gumption to oversee this kind of a redo. Maybe someone else will.
Ehud Gavron
Tucson, Arizona, US
we were able to significantly reduce CPU usage like this:
cryptsetup refresh --persistent --allow-discards --perf-no_read
_workqueue --perf-no_write_workqueue <name of encrypted mapping>
where the name of the encrypted mapping is /dev/mapper/<name> without the /dev/mapper
–allow-discards is optional, but a lot of SSDs will get really slow over time if you dont fstrim them and this lets you do that.
anyways this takes read CPU usage from 40-50% to more like 20-25%. it doesn’t speed up the encryption/decryption but it makes the CPU usage less so you arent slowing down other programs as much. it basically reduces some memcopies and marshalling some data around which is really beneficial on SSDs. --persistent means that you can run this once and its persistent. it doesnt speed things up but doesnt slow things down either. i recommend it so far.
2 Likes
I’m a total noob on this topic, so I wanted to find out what the implications of --allow-discards and --perf-no_read_workqueue --perf-no_write_workqueue actually are.
You can find out your current settings by running:
sudo cryptsetup luksDump /dev/nvme0n1 | grep Flags
As for --allow-discards, the manual page of cryptsetup-refresh says:
WARNING: This command can have a negative security impact because it can make filesystem-level operations visible on the physical device. For example, information leaking filesystem type, used space, etc. may be extractable from the physical device if the discarded blocks can be located later. If in doubt, do not use it.
For --perf-no_read_workqueue --perf-no_write_workqueue, the ArchWiki says:
The
no_read_workqueueandno_write_workqueueflags were introduced by internal Cloudflare research Speeding up Linux disk encryption made while investigating overall encryption performance. One of the conclusions is that internal dm-crypt read and write queues decrease performance for SSD drives. While queuing disk operations makes sense for spinning drives, bypassing the queue and writing data synchronously doubled the throughput and cut the SSD drives’ IO await operations latency in half.
1 Like
yeah --allow-discards you need to decide whether to use it based on your threat model. for me, i just dont want the unencrypted data to be on the drive when i get rid of it or it gets stolen, mainly. so leaking used space is fine for me. in the worst case, it is conceptually similar to if the filesystem was unencrypted, but all the file names and file contents were encrypted. you’d have to be pretty skilled as an attacker to even get to that point of analyzing the sidechannel data too. --allow-discards doesn’t matter for CPU usage also, its just a long term SSD performance thing.
the perf ones are uncontroversial by comparison. i do not see the increased throughput that was mentioned, but I do see much less CPU used. this makes sense to me because cloudflare is almost certainly on faster CPUs with faster enterprise hard drives so the performance characteristics between them are different. but it cuts out a whole bunch of queueing that otherwise has to be managed and leads to extra memcopies, kernel task scheduling, etc. etc.
My last screenshots were from imx8mq. Here are some from my LS1028A with an Intenso Top Performance SSD. First without encryption:
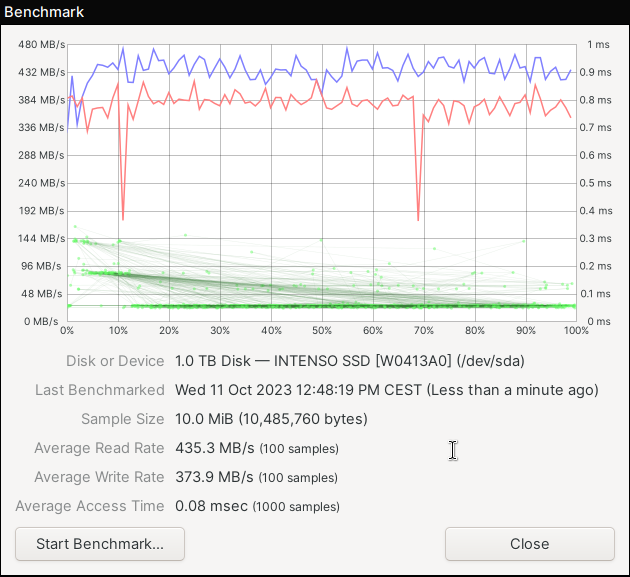
And here with encryption:
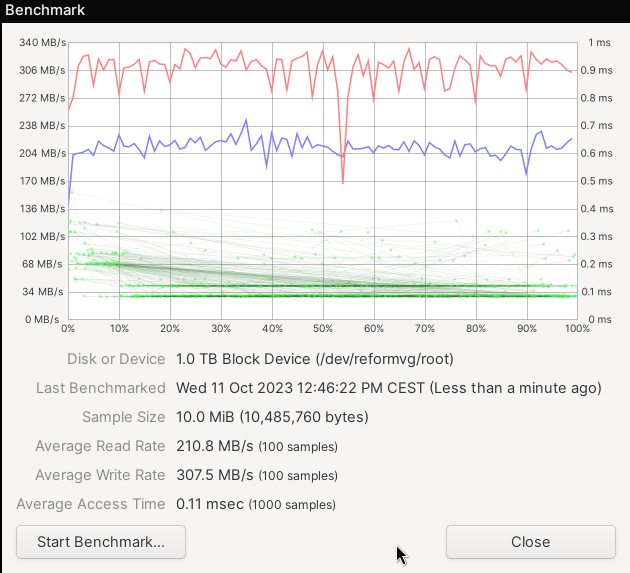
1 Like